UDP
- 端口:端口是为了支持在同一个电脑上多个程序同时在不同的TCP连接中收发信息而服务的。一个套接字对应一个进程,而一个套接字由一个四元组定义(源端口、源IP、目标端口、目标IP)。
- 可靠数据服务:
- 保证报文段的交付(对应丢包)
- 报文段的按序交付(对应乱序)
- 保证报文段的数据完整性(对应数据中比特发生改变)。
- UDP不是可靠数据服务,TCP是可靠数据服务
- 一些应用使用UDP的原因:
- 简单、没有额外功能,适合作文章
- 无需建立连接(没有握手,快)
- 无连接状态(本地存储开销小)
- 分组首部开销小(N/R小)
- 检验和
- 溢出后回卷(溢出指最左的1超出了能承受的最高位;回卷指的是把这个1加回到个位)
- UDP将所有16比特字的和进行反码,形成检验和
- 接收方将所有16比特相加,若为全1,则没有差错(数字电路课的基本知识)
- 端到端原则:
- wiki: The end-to-end principle is a design framework in computer networking. In networks designed according to this principle, application-specific features reside in the communicating end nodes of the network, rather than in intermediary nodes, such as gateways and routers, that exist to establish the network.
- 原论文表述: Functions placed at low levels of a system may be redundant or of little value when compared with the cost of providing them at that low level.
- 我的理解:底层网络设计应尽可能地简洁,把差错检测等功能交由端处理。
可靠数据传输
- 亚当想跟夏娃表白。他要向她传达四个字:“我”“喜”“欢”“你”。
- 亚当站在山谷的一边,夏娃站在另一边。
- 山谷间很安静。亚当直接对夏娃喊道:“我!喜!欢!你!”夏娃听得很清楚。故事完。
- 两人距离很远,仅凭亚当的声音传达不到。但夏娃的嗓门很大,亚当听得见。有一只鹦鹉在山谷间飞来飞去,它会听见亚当说什么,然后向夏娃复述。且它有时复述得不标准。
- 亚当喊“我“”喜”时,鹦鹉转述无差错。夏娃一一回应:“听到了!”“听到了!”
- 亚当喊:“欢!”
- 夏娃只听见鹦鹉复述:fuan!
- 差错检测:夏娃发现fuan不是一个中文汉字。
- 接收方反馈:夏娃回答亚当:“你说啥嘞!”
- 重传:亚当听见夏娃的反馈,再喊“欢!”
- 夏娃喊累了,嗓门变小了。于是鹦鹉不仅会向夏娃转述亚当说了什么,还会向亚当转述夏娃说了什么。且它有时复述得不标准。(ACK、NAK受损)
- 当夏娃问亚当“你说啥嘞”时,鹦鹉转述为“你suo sa 嘞”,亚当有这几种做法:
- 问夏娃:“你说什么!”但这会带来风险:鹦鹉向夏娃转述为“你suo sen么!”夏娃依然听不清,然后回问亚当,亚当依然听不清,回问夏娃,进入无限循环。
- 亚当不知道夏娃回答什么,于是再讲一遍:“欢!”。这会导致夏娃不知道亚当想说的是“我喜x欢”还是“我喜欢”。
- 亚当和夏娃知道鹦鹉会把“说”变为“suo”,把“啥”变为“sa”,因此他们能正常沟通(增加足够的检验和比特)。
- 解决方法为:亚当每次都把他要说的字的序号讲出来。比如他不知道夏娃回答了什么,于是喊:“第三个字!欢!”这样夏娃就知道亚当想说“我喜欢”而不是“我喜x欢”了。
- 当夏娃问亚当“你说啥嘞”时,鹦鹉转述为“你suo sa 嘞”,亚当有这几种做法:
- 鹦鹉不仅复述时不标准,而且有时候不会帮忙转述。(丢包)
- 解决方法:亚当喊完一个字后,在山谷这边的苹果树下啃苹果,如果啃完一个苹果夏娃还没回应,那么要么是夏娃没听见,要么是夏娃的回应被鹦鹉吞了。于是他啃完苹果后,又喊:“第三个字!欢!”然后开始啃另一个苹果,直到他听见为止。他会只喊“第三个字!欢!”,知道他听懂夏娃的回应为止。
- 如果鹦鹉不再想出新的捣乱方法,那么亚当能用方法四和夏娃正确地沟通。但是亚当感觉很心累。为什么他不能一次性喊:“我喜欢你!”呢。(流水线)
- 假设夏娃能够一次性记住四个或以上数量的字,那么亚当能这么一次性喊掉。
- 如果夏娃不能的话……
回退N步(GBN, go-back-N)
照车小胖写了如下例子。
亚当隔着山头向夏娃抛玉米棒。
亚当抛玉米棒1、2、3、4、5、6……
夏娃只有一个能容纳3个玉米棒的篮子,于是她只好一次性收3个玉米棒,并告诉亚当:“收到1”“收到2”“收到3”。
这里我们发现,夏娃只能收三个玉米棒,只意味着如果亚当每次抛4个及以上数量的玉米棒,必定有至少一个玉米棒夏娃没有收到。
亚当也发现了这点,于是改变他的策略,他也造了一个只有三个玉米棒的篮子,每次扔玉米棒时都从篮子里拿要扔的玉米。他重新抛玉米棒:玉米棒1、2、3. 他开始啃苹果,等待夏娃的回应。
夏娃说:“收到1”“收到2”“收到3” 然后开始把篮子里的玉米棒捧回家。
亚当听到了夏娃说“收到1”“收到2”,于是他把自己篮子里玉米棒1、玉米棒2扔掉,放进了玉米棒4、玉米棒5.(其实应该是上层调用) 亚当没有听到“收到3”。一个苹果啃完了,夏娃还没有回应。(超时事件)于是他重新抛了玉米棒3、玉米棒4、玉米棒5。
夏娃发现这个玉米棒3她已经有了,于是回答亚当:“收到3”。然后她把玉米棒4、玉米棒5放进了空的篮子。回答亚当:“收到4”“收到5”
亚当听到了夏娃的回应,把他的篮子刷新为玉米棒6、玉米棒7、玉米棒8,并且抛给夏娃。开始啃苹果。
夏娃依次收到玉米棒6、玉米棒8、玉米棒7. 于是她扔掉不按顺序到来的玉米棒,回应亚当“收到6”“收到6”“收到6”。(累计确认)
亚当听见收到6,于是把他的篮子刷新为玉米棒7、玉米棒8、玉米棒9。苹果啃完了,发现夏娃没回应玉米棒7. (超时事件)于是扔玉米棒7、8、9.
选择重传(SR, selective repeat)
夏娃觉得她依次收到玉米棒6、玉米棒8、玉米棒7时,没有必要丢掉乱序的玉米棒。她回答“收到6”“收到8”“收到7”。这就是选择重传的想法:确认一个正确接收的分组而不管其是否按序。
当装玉米棒的篮子太大时,其和编号之间会出现困境:夏娃不知道只是一次新分组还是重传。例如:
亚当和夏娃各有一个装四个玉米棒的篮子;
亚当向夏娃扔玉米棒0、1、2、3,夏娃依次回应:“收到0”“收到1”“收到2”“收到3”。
亚当听见了“收到0”“收到1”“收到2”,但是没听见“收到3”,他扔掉了第0、1、2个玉米棒,并放入第4、5、6个玉米棒,分别编号为玉米棒0、1、2. 他啃完一个苹果,还是没听见夏娃的回应,于是开始扔玉米棒3、0、1、2.
夏娃接收到了玉米棒3,并认为这是一个新的玉米棒。此刻产生问题:这本应是一个已接收过的玉米棒。
篮子内的玉米棒数量不应太多。
应该怎么处理窗口(篮子大小)和编号之间的关系?
知乎有肖太龙回答如下:

TCP
极其复杂。
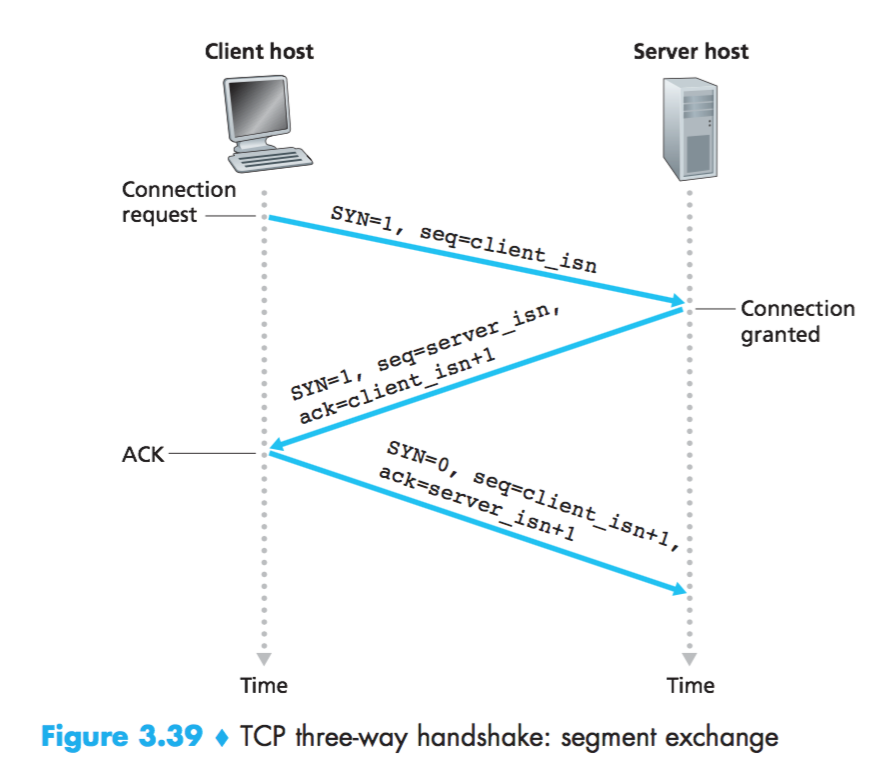
序号与确认号
- 确认号:此时夏娃不再说“收到1”“收到2”“收到3”了,而是说“我要2”“我要3”“我要4”。
- 序号:报文段首字节的字节流编号。理解:下一次的序号减去这一次的序号等于这一次的字节流大小。
- TCP是累积确认的。累积确认的意思是默认被确认的报文段及在其序号之前的报文段都是已接受到的。
亚当要啃多久苹果
跟页面置换的老化算法有点像。当时$\alpha$取的$\frac{1}{2}$,方便位移实现。
- SampleRTT:在特定时间为只传输了一次的报文段测一次RTT
- EstimatedRTT: EstimatedRTT = $(1-\alpha)\cdot$ EstimatedRTT + $\alpha \cdot$ SampleRTT.
- DevRTT = $(1-\beta$) $\cdot$ DevRTT + $\beta \cdot$ $|$ SampleRTT-EstimatedRTT $|$
- 超时间隔设为 TimeoutInterval = EstimatedRTT + 4 $\cdot$ DevRTT,但是当超时的时候会重传并时间翻倍,不再超时时回到TimeInterval。(非常棒的设计!用发送频率的降低帮助了拥塞控制)
TCP是SR还是GBN
都不是。或者说是他们的混合体。
TCP的重传当且仅当:1、相应报文段的定时器超时;2、相应报文段的ACK被响应3次。(快速重传)
假设亚当向夏娃扔了玉米棒子0、玉米棒子1、玉米棒子2、玉米棒子3。且双方都确认他们在使用TCP。亚当启动定时器。
假设夏娃依次收到了玉米棒子0、玉米棒子1和玉米棒子3. 她会返回给亚当“ACK1”、“ACK2”、“ACK2”。她会把这些玉米棒子都放在篮子里。(缓存乱序的报文段是SR的特点)她不会返回“ACK4”,因为TCP是累积确认的,而夏娃没有收到玉米棒子2.(累积确认是GBN的特点)
假设亚当在定时器结束前收到了“ACK1”“ACK2”“ACK2”。计时器时间到了,亚当需要重发。他无法确保夏娃是否收到玉米棒子3,因此他只给夏娃扔玉米棒子2,不扔玉米棒子3.(这样的好处是减少带宽占用,而GBN会把一并把所有未被确认的报文段都扔出去)
夏娃收到玉米棒子2,现在篮子里有玉米棒子0-3,于是她告诉亚当”ACK4”.
综上看出,TCP是GBN与SR协议的混合体
为什么有快速重传?
我其实不太赞同TCP快速重传为什么是三次冗余ack,这个三次是怎么定下来的?中车小胖的回答中的一点,我认为三个冗余ACK相当于四个相同ACK。
如果有两个来临位置相互交换,如夏娃先收到第N+1个玉米棒子,再收到第N个玉米棒子,那么她会发:“ACK N”“ACK N+2”。由于之前收到第N-1个玉米棒子的时候夏娃也发出了”ACK N”,因此有一个冗余ACK。
如果乱序为N+2、N+1、N,则夏娃会发:“ACK N”“ACK N”“ACK N+3”,这时出现两个冗余ACK。
三个冗余ACK表明大概率是丢包的情况,且网络的拥塞情况并不严重(因为至少有三个序号比未确认包的最小序号大的包到达了目的地)。因为拥塞情况并不严重,因此可以立即重传,又省时间(不需要等到超时)、又充分利用带宽。
流量控制
- rwnd:接收窗口,标明接收方还有多少的缓存空间
接收方每次通过piggybacking的方式告诉发送方自己rwnd的大小,发送方需要保证整个生命周期中:$$\text{LastByteSent - LastByteAcked}\leq \text{rwnd}$$
这是为了防止发送方的发送数据在接收方的接收缓存中溢出。
- 特例:当接收方告诉发送方rwnd为0时,发送方仍得持续向接收方发送只有一个字节数据的报文段,直到发送方知道接收方的rwnd不再为0。
连接建立与拆除
三次握手
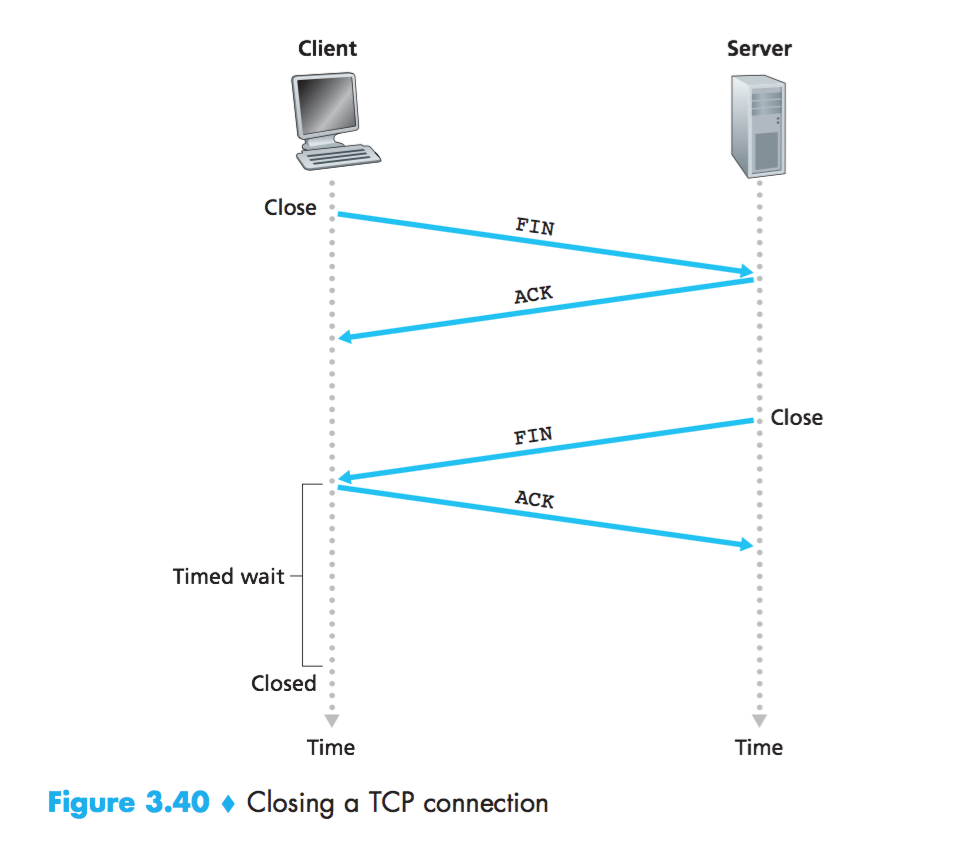
四次挥手
拥塞的原理
- 分组的到达速率接近链路容量时,分组经历巨大的排队时延。
- 发送方必须执行重传以补偿因为缓存溢出而丢弃(丢失)的分组。
- 时延带来的不必要重传使得路由器转发了不必要的分组副本。
- 一个分组被下游路由器丢弃时,每个上游路由器用于转发该分组而消耗的传输容量被浪费了。(跟操作系统里的死锁差不多)
拥塞控制的方法
端到端的拥塞控制:
本质是通过控制传输速率来减小拥塞程度。
网络辅助的拥塞控制:
ATM ABR拥塞控制框架:一个基于速率的控制系统,通过在链路的数据段流中插入交换机的反馈信息(如速率、拥塞指示)来标明发送方怎样调整速率。
TCP拥塞控制
超级超级复杂。特性为:加性增、乘性减。
- congestion window: $$\text{LastByteSent - LastByteAcked}\leq\min\left\{\text{cwnd, rwnd}\right\}$$
慢启动 (Slow Start)
cwnd随着RTT指数型增长,直到:
- 超时,ssthresh=cwnd/2,设cwnd为1(MSS)
- 检测到3个冗余ACK, ssthresh=cwnd/2,cwnd=ssthresh+3*MSS,进入快速恢复
- cwnd超过ssthresh,进入拥塞避免(加性增)
拥塞避免 (Congestion Avoidance)
cwnd随着RTT线性增长,直到:
- 超时,ssthresh=cwnd/2,设cwnd为1(MSS),进入慢启动
- 检测到3个冗余ACK,ssthresh=cwnd/2,cwnd=ssthresh+3*MSS,进入快速恢复
快速恢复 (Fast Recovery)
- 若有重复ACK到来,加性增cwnd
- 若没有重复ACK到来:
- 若超时,ssthresh=cwnd/2,设cwnd为1(MSS),进入慢启动
- 若有新ACK到来,cwnd=ssthresh,进入拥塞避免
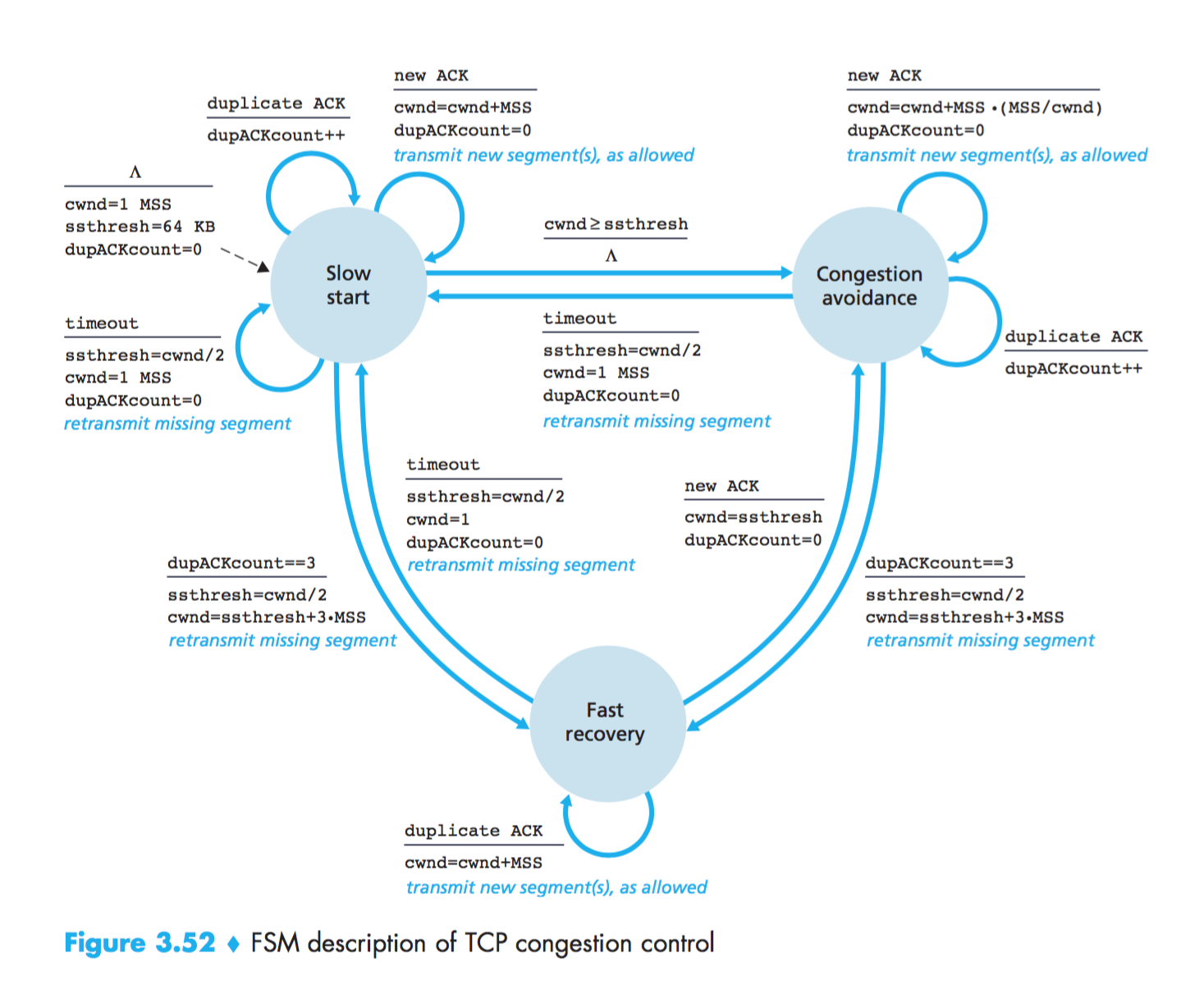
疑问
快速恢复啥玩意啊?
假设编号为0-15.
亚当先给夏娃扔了1个玉米棒子:编号为0,夏娃:“ACK 0”
亚当又扔了2个。夏娃:“ACK 1”“ACK 2”
亚当又扔了四个。夏娃:”ACK 3””ACK 4””ACK 5””ACK 6”
亚当扔了8个。夏娃:[“ACK %d” %(i) for i in range(7,15)] (亚当收到夏娃所有回应后,此时 cwnd为16)
亚当给夏娃扔了16个玉米棒子:分别编号为15, 0, 1, 2, ……, 14,
夏娃依次收到了棒子15, 0-2, 4-14, 这意味着3号玉米棒子路上被偷了。且夏娃的篮子只能放10个玉米棒子,于是她回了10个ACK
亚当收到了夏娃的”ACK 0””ACK 1””ACK 2””ACK 3””ACK 3””ACK 3””ACK 3””ACK 3””ACK 3””ACK 3”,请问亚当如何判断下次他该给夏娃几个玉米棒子?(即,亚当如何知道夏娃的篮子最多能放几个玉米棒子?)
亚当发现夏娃回了三个冗余”ACK 3”,于是进入快速恢复,此时cwnd为16+4=20,于是ssthresh设为10,cwnd重新设为13,重传3号棒子。
在这三个冗余之后亚当又收到了3个冗余,因此cwnd设为16,传新的segment:棒子15、棒子0、棒子1、棒子2。新的棒子3不能传,因为老的棒子3的ACK还没来。
亚当等待着ACK。
若ACK3来临,进入拥塞避免,即亚当成功知道夏娃篮子大小为10(此时cwnd=ssthresh=10);若ACK3没有来临,进入慢启动,此时ssthresh为5,之后当cwnd>ssthresh时,进入拥塞避免,增性加,最终仍可知道夏娃篮子大小小于等于10.
简而言之,快速恢复给慢启动、拥塞避免提供了避免乘性减带来的cwnd减小的幅度过大以导致cwnd回到应有状态所经过的传输回合较大的问题的途径。
有了慢启动,为啥还要拥塞避免啊?
慢启动和拥塞避免之间的循环就像是数值计算里的逼近方式:先判断出一个数的对数为多少,然后再在拥有相同对数取整的数字中线性寻找这个数字。
线性逼近的过程所耗费的步骤数长,且所处的区域较为靠近目标数字,因此速率较高、持续时间较长,适合长时间高效地传输。
当发送方发现超时时,它需要控制阻塞,因此ssthresh的设置告诉了它阻塞的大致阈值,此时转到慢启动状态有两个好处:1、cwnd从1开始,因此能从个人的角度帮助阻塞大幅度缓解;2、启动速度快(指数型),能快速重新定位新的阻塞阈值,亦或回到原先的传输速率区间。
不得让人感慨这精妙的设计。
公平性
书上的直观解释挺好的。
此外UDP占用链路、并行TCP连接使得每台主机之间不太公平(拥有相似的链路流量),令人怀疑劣币驱逐良币的趋势。当然由UDP的不可靠也是会带来UDP和TCP之间的取舍的。只希望能从我做起:只取所需,不要浪费吧。